RTC export (RTC_export.py)
As I explained in the previous article (part 1), I use the RTC REST API instead of the RTC CLI to export the history from RTC because the RTC CLI is not reliable. However, the official (documented) REST API is too limited. The RTC Webgui also uses the REST API, but extends the REST API with an unofficial, undocumented REST API calls. These (official and unofficial) GET requests return JSON responses containing the information we are looking for. By analyzing the browser messages, you know the exact GET request (https) and the response (JSON) communication.
Reverse engineer GET request/response of the RTC Webgui
To figure out how the headers of the GET requests that the RTC Webgui uses look like, we open the page in the Webgui that shows the information. For example, login to RTC and open the page that shows all streams in Firefox, then press CTRL-SHIFT-E (Web Developer > Network), lookup and select the GET request with JSON output of the stream information (in this case it is typically the last GET with JSON response), find the URL in the Headers section and the JSON response in the Response section.
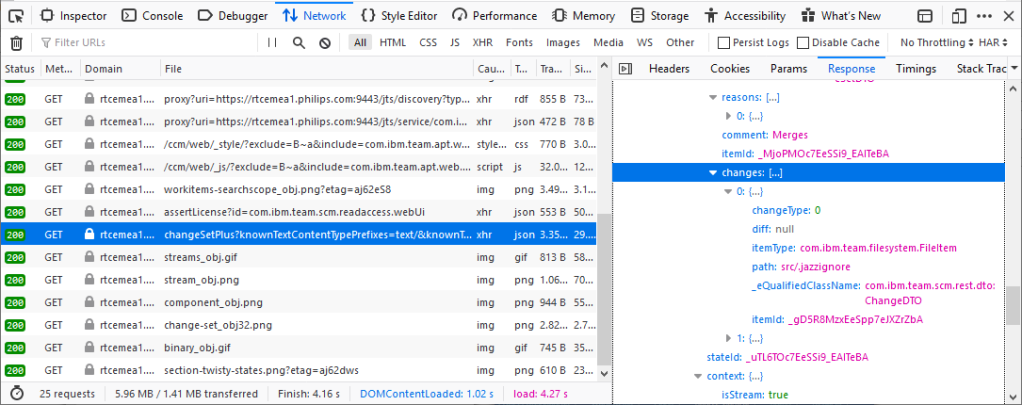
The advantage of JSON is that Python dictionaries use about the same syntax. This way, you can reverse engineer the REST API used by the the RTC Webgui and translate this into GET/JSON calls in Python quite easily.
#----------------------------------------------------------------------
# Extract information from RTC
class RTC:
def __init__(self):
self.session = requests.Session()
self.login()
#----------------------------------------------------------------------
# Login to RTC
def login(self):
response = self.session.post("%s/auth/j_security_check" % RTC_URI, data={'j_username': RTC_USERNAME, 'j_password': RTC_PASSWORD})
assert 'net.jazz.web.app.authfailed' not in response.text, 'Failed to login'
#----------------------------------------------------------------------
# Get all project areas from RTC
def get_all_project_areas(self):
url = '%s/service/com.ibm.team.process.internal.service.web.IProcessWebUIService/allProjectAreas' % RTC_URI
response = self.session.get(url, headers={'accept': 'text/json'})
response = json.loads(response.text)['soapenv:Body']['response']['returnValue']['values']
return [{'name':v['name'], 'summary':v['summary'], 'ID':v['itemId']} for v in response if not v['archived']]
This example shows the get_all_project_areas function uses the internal web services and translates the JSON response into a dictionary structure. Only the ‘value’ data from the JSON response is relevant. The return value of the function is created by a Python “generator” construct to build a list (array) of relevant values from the response (list). Being new to Python, I find this a very powerful and beautiful mechanism.
Exporting RTC history
Now that we know how to extract data from RTC using the REST API used by the RTC Webgui, we can go into the export logic. First of all, we need to export from RTC now, what we need to imported into a Git repository later. There are 2 types of components in a stream:
- Components with history
- Components without history
Components without history are just a reference to a baseline of the component from another stream. Without history, there is no point in exporting the components. The history of the components with history need to be exported. These specific components are defined in components_of_interests. And the streams from which the components are exported are defined in streams_of_interest. In my case, I only export from a single stream, to be imported into a single Git repository later.
For example, exporting the history of 4 components from 2 streams, requires the following definition:
streams_of_interest = [
'streamA',
'streamB'
]
components_of_interest = {
'streamA': [
'component1',
'component2'
]
'streamB': [
'component3',
'component4'
]
}
So the outer loops go through the streams of interest and the components of interest:
rtc = RTC()
for stream in rtc.get_all_streams():
if stream['name'] not in streams_of_interest:
continue
for component in rtc.get_components(stream):
if component['name'] not in components_of_interest[stream['name']]:
continue
print("Retrieving history for %s/%s" % (stream['name'], component['name']))
for changesets in rtc.get_changesets(stream, component):
for changeset in changesets:
...
changeset['files'] = rtc.get_changeset_detail(stream, component, changeset)
for file in [f for f in changeset['files'] if 'itemId' in f]:
...
rtc.get_file(file['itemId'], file['afterStateId'], file_path)
...
target = os.path.join(output_path, 'changesets', stream['name'], changeset['ID'])
os.makedirs(target, exist_ok=True)
with open(os.path.join(target, 'meta.json'), 'w') as fp:
json.dump(changeset, fp, indent=4)
Of each component, all changesets are exported. Per changset, I need to know which files have changed. The content of the files is saved (so it can be imported in Git later on), and the meta-data of the changeset is saved in a meta.json file.
In a similar way, snapshots and baselines are exported, except that they don’t need a double loop, as far as I can tell, and they don’t need to save files.
for snapshot in rtc.get_snapshots(stream):
print("Retrieving baselines for snapshot %s/%s" % (stream['name'], snapshot['name']))
...
for baseline in rtc.get_baselines(snapshot):
if baseline['componentName'] not in components_of_interest[stream['name']]:
continue
...
target = os.path.join(output_path, 'baselines', stream['name'], baseline['ID'])
os.makedirs(target, exist_ok=True)
with open(os.path.join(target, 'meta.json'), 'w') as fp:
json.dump(baseline, fp, indent=4)
...
target = os.path.join(output_path, 'snapshots', stream['name'], snapshot['ID'])
os.makedirs(target, exist_ok=True)
with open(os.path.join(target, 'meta.json'), 'w') as fp:
json.dump(snapshot, fp, indent=4)
A stream consists of a set of components. A snapshot is a set of baselines for the components of the stream. Since we are only exporting the components_of_interest, the script only saves the baselines for those components. Unfortunately, I did not find a way to show all baselines of the components, only the baselines present in a snapshot of the stream.
Important to know is that a snapshot contains new component baselines only for the components that have changed since the previous snapshot. For other (not changed) components, the snapshot contains the same baselines as in the previous snapshot. This means that going through the snapshots, I will find the same baselines over and over again and only a few new ones for the components of interest.
Export details
Maximum batch size
In the middle of the changeset retrieval, you see this double ‘for’ loop.
for changesets in rtc.get_changests(stream, component):
for changeset in changesets:
The reason for the double loop is that RTC only returns the changesets in batches of maximum 100 changesets. The inner loop processes the changesets of a batch; the outer loop retrieves the next batch. The get_changesets function uses a neat generator mechanism in Python (yield) to produce these successive batches:
#----------------------------------------------------------------------
# Get change sets from a stream in RTC
def get_changesets(self, stream, component):
# This function will yield changeset arrays with the batch size
# The RTC REST api does not support values higher than 100
batch_size = 100
last = None
while True:
...
params = {'n': batch_size, 'path': 'workspaceId/%s/componentId/%s' % (stream['ID'], component['ID'])}
if last != None:
params['last'] = last['ID']
url = "%s/service/com.ibm.team.scm.common.internal.rest.IScmRestService2/historyPlus" % RTC_URI
response = self.session.get(url, params=params, headers={'accept': 'text/json'})
response = json.loads(response.text)['soapenv:Body']['response']['returnValue']['value']['changeSets']
changesets = response
if last != None:
# The first changeset is the same as the last changeset from the previous batch
changesets = changesets[1:]
changesets = [{
'objecttype':'changeset',
'date': changeset['changeSetDTO']['dateModified'],
'label': [reason['label'] for reason in changeset['changeSetDTO']['reasons']] if 'reasons' in changeset['changeSetDTO'] else [],
'message': changeset['changeSetDTO']['comment'],
'author': '%s <%s>' % (changeset['changeSetDTO']['author']['name'], changeset['changeSetDTO']['author']['emailAddress']),
'modified': changeset['changeSetDTO']['dateModified'],
'added': changeset['changeSetDTO']['dateAdded'],
'ID': changeset['changeSetDTO']['itemId'],
'component': component['name'],
'componentID': component['ID'],
} for changeset in changesets]
yield changesets
# Stop if less than batch size are returned
if len(response) < batch_size:
break
last = changesets[-1]
Yield acts similar to return (i.e. return a batch of max 100 changesets) but instead of ending the function (as return would do) processing continues with the while True loop to retrieve the next batch of changesets. This infinite loop is ended by the break. On the outside, the get_changesets function will return an array (list) of return values of the successive yield instructions, i.e. all batches of max 100 changsets. This is called a “generator” in Python.
Each exported changeset consists of the following fields, which is stored in a meta.json file in the folder identified by the changeset UUID.
'objecttype'– changeset, baseline or snapshot'date'– datetime stamp of the changeset, typically latest modification date'label'– reason of the change, typically the workitem linked to the changeset'message'– comment provided with the changeset by the developer'author'– name and email address of the developer'modified'– date of the latest modification of the changeset'added'– creation date of the changeset'ID'– UUID of the changeset'component'– component modified by the changeset'componentID'– UUID of the component'files'– field filled by theget_changeset_detailfunction'path'– relative path of the file'type'– type of change, e.g. added, modified, renamed, deleted'itemType'– type of object, e.g. File, Folder, SymbolicLink'beforepath'– relative path of the file before a rename or move'size'– size of the file'itemId'– UUID of the file'afterStateId'– UUID of the version of the file
Non-chronological history
Another problem I ran into is that the history (of a component) is not chronological. For example, I found a sequence of changesets of a component dated in 2019 with a changeset from 2018 in between. So, I wondered how that is possible.
The reason for the non-chronological history is that the date of a changeset is de latest modification date of the changeset, not the delivery date into the stream. If a changeset is latest modified in 2018, but delivered to the stream in 2019, it sits in between the changesets created/modified and delivered in 2019.
Although the history itself is not chronological, RTC (i.e. the REST API) returns the history in the correct sequential order: newest changeset first, oldest changeset last. This is the same sequence as shown in the RTC Webgui. To keep track of the correct sequential order of the changesets, I add a sequence number to the changesets. With it, the Git import can reconstruct the right sequence order for the import.
changeset['seqnr'] = seqnr
seqnr += 1
Incremental export
Now suppose you have run the export for a number of hours and there is a hickup in the communication with the RTC server. The script stops. When you restart the script, you don’t want it to start over from the beginning and redo what it already did. But how do you know where it left off?
Well, you don’t! The script does go over all changesets from the beginnen, except that files already exported are not exported again. Instead it reads the meta.json file and updates the sequence number.
target = os.path.join(output_path, 'changesets', stream['name'], changeset['ID'])
json_file = os.path.join(target, 'meta.json')
if os.path.exists(target):
with open(json_file) as fp:
changeset = json.load(fp)
print("\tAlready exported changeset", changeset['ID'], changeset['date'], "%s/%s" % (stream['name'], component['name']))
changeset['seqnr'] = seqnr
seqnr += 1
If the changeset was not exported yet, the files of the changeset are downloaded and saved. Then the meta.json file is written. That way it is assured that the changesets get the correct sequence number.
if not os.path.exists(target):
os.makedirs(target, exist_ok=True)
changeset['files'] = rtc.get_changeset_detail(stream, component, changeset)
for file in [f for f in changeset['files'] if 'itemId' in f]:
file['seqnr'] = seqnr
seqnr += 1
file_path = os.path.join(target, component['name'], file['path'].replace("/", "\\"))
# Prefix the path with \\?\ to allow paths longer than 255 characters
file_path = "\\\\?\\%s" % file_path
os.makedirs(os.path.dirname(file_path), exist_ok=True)
rtc.get_file(file['itemId'], file['afterStateId'], file_path)
os.makedirs(target, exist_ok=True)
with open(os.path.join(target, 'meta.json'), 'w') as fp:
json.dump(changeset, fp, indent=4)
Conclusion
Now that we have the history from all components of interested exported from the stream of interest, we can go to importing it in Git. In principle, this involved replaying the changesets from the exported history and applying the baselines. But in practice, there are a few challenges to overcome. That is something for the next article.